 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE-Globe: Scalable $ε$-Global Verification of Neural Networks via Tight Upper Bounds and Pattern-Aware Branching
Feb 04, 2026Neural networks achieve strong empirical performance, but robustness concerns still hinder deployment in safety-critical applications. Formal verification provides robustness guarantees, but current methods face a scalability-completeness trade-off. We propose a hybrid verifier in a branch-and-bound (BaB) framework that efficiently tightens both upper and lower bounds until an $ε-$global optimum is reached or early stop is triggered. The key is an exact nonlinear program with complementarity constraints (NLP-CC) for upper bounding that preserves the ReLU input-output graph, so any feasible solution yields a valid counterexample and enables rapid pruning of unsafe subproblems. We further accelerate verification with (i) warm-started NLP solves requiring minimal constraint-matrix updates and (ii) pattern-aligned strong branching that prioritizes splits most effective at tightening relaxations. We also provide conditions under which NLP-CC upper bounds are tight. Experiments on MNIST and CIFAR-10 show markedly tighter upper bounds than PGD across perturbation radii spanning up to three orders of magnitude, fast per-node solves in practice, and substantial end-to-end speedups over MIP-based verification, amplified by warm-starting, GPU batching, and pattern-aligned branching.
Constraint-Informed Active Learning for End-to-End ACOPF Optimization Proxies
Nov 09, 2025

This paper studies optimization proxies, machine learning (ML) models trained to efficiently predict optimal solutions for AC Optimal Power Flow (ACOPF) problems. While promising, optimization proxy performance heavily depends on training data quality. To address this limitation, this paper introduces a novel active sampling framework for ACOPF optimization proxies designed to generate realistic and diverse training data. The framework actively explores varied, flexible problem specifications reflecting plausible operational realities. More importantly, the approach uses optimization-specific quantities (active constraint sets) that better capture the salient features of an ACOPF that lead to the optimal solution. Numerical results show superior generalization over existing sampling methods with an equivalent training budget, significantly advancing the state-of-practice for trustworthy ACOPF optimization proxies.
Hadamard Attention Recurrent Transformer: A Strong Baseline for Stereo Matching Transformer
Jan 02, 2025In light of the advancements in transformer technology, extant research posits the construction of stereo transformers as a potential solution to the binocular stereo matching challenge. However, constrained by the low-rank bottleneck and quadratic complexity of attention mechanisms, stereo transformers still fail to demonstrate sufficient nonlinear expressiveness within a reasonable inference time. The lack of focus on key homonymous points renders the representations of such methods vulnerable to challenging conditions, including reflections and weak textures. Furthermore, a slow computing speed is not conducive to the application. To overcome these difficulties, we present the \textbf{H}adamard \textbf{A}ttention \textbf{R}ecurrent Stereo \textbf{T}ransformer (HART) that incorporates the following components: 1) For faster inference, we present a Hadamard product paradigm for the attention mechanism, achieving linear computational complexity. 2) We designed a Dense Attention Kernel (DAK) to amplify the differences between relevant and irrelevant feature responses. This allows HART to focus on important details. DAK also converts zero elements to non-zero elements to mitigate the reduced expressiveness caused by the low-rank bottleneck. 3) To compensate for the spatial and channel interaction missing in the Hadamard product, we propose MKOI to capture both global and local information through the interleaving of large and small kernel convolutions. Experimental results demonstrate the effectiveness of our HART. In reflective area, HART ranked \textbf{1st} on the KITTI 2012 benchmark among all published methods at the time of submission. Code is available at \url{https://github.com/ZYangChen/HART}.
Motif Channel Opened in a White-Box: Stereo Matching via Motif Correlation Graph
Nov 19, 2024



Real-world applications of stereo matching, such as autonomous driving, place stringent demands on both safety and accuracy. However, learning-based stereo matching methods inherently suffer from the loss of geometric structures in certain feature channels, creating a bottleneck in achieving precise detail matching. Additionally, these methods lack interpretability due to the black-box nature of deep learning. In this paper, we propose MoCha-V2, a novel learning-based paradigm for stereo matching. MoCha-V2 introduces the Motif Correlation Graph (MCG) to capture recurring textures, which are referred to as ``motifs" within feature channels. These motifs reconstruct geometric structures and are learned in a more interpretable way. Subsequently, we integrate features from multiple frequency domains through wavelet inverse transformation. The resulting motif features are utilized to restore geometric structures in the stereo matching process. Experimental results demonstrate the effectiveness of MoCha-V2. MoCha-V2 achieved 1st place on the Middlebury benchmark at the time of its release. Code is available at https://github.com/ZYangChen/MoCha-Stereo.
LEVIS: Large Exact Verifiable Input Spaces for Neural Networks
Aug 16, 2024



The robustness of neural networks is paramount in safety-critical applications. While most current robustness verification methods assess the worst-case output under the assumption that the input space is known, identifying a verifiable input space $\mathcal{C}$, where no adversarial examples exist, is crucial for effective model selection, robustness evaluation, and the development of reliable control strategies. To address this challenge, we introduce a novel framework, $\texttt{LEVIS}$, comprising $\texttt{LEVIS}$-$\alpha$ and $\texttt{LEVIS}$-$\beta$. $\texttt{LEVIS}$-$\alpha$ locates the largest possible verifiable ball within the central region of $\mathcal{C}$ that intersects at least two boundaries. In contrast, $\texttt{LEVIS}$-$\beta$ integrates multiple verifiable balls to encapsulate the entirety of the verifiable space comprehensively. Our contributions are threefold: (1) We propose $\texttt{LEVIS}$ equipped with three pioneering techniques that identify the maximum verifiable ball and the nearest adversarial point along collinear or orthogonal directions. (2) We offer a theoretical analysis elucidating the properties of the verifiable balls acquired through $\texttt{LEVIS}$-$\alpha$ and $\texttt{LEVIS}$-$\beta$. (3) We validate our methodology across diverse applications, including electrical power flow regression and image classification, showcasing performance enhancements and visualizations of the searching characteristics.
Cascading Blackout Severity Prediction with Statistically-Augmented Graph Neural Networks
Mar 22, 2024



Higher variability in grid conditions, resulting from growing renewable penetration and increased incidence of extreme weather events, has increased the difficulty of screening for scenarios that may lead to catastrophic cascading failures. Traditional power-flow-based tools for assessing cascading blackout risk are too slow to properly explore the space of possible failures and load/generation patterns. We add to the growing literature of faster graph-neural-network (GNN)-based techniques, developing two novel techniques for the estimation of blackout magnitude from initial grid conditions. First we propose several methods for employing an initial classification step to filter out safe "non blackout" scenarios prior to magnitude estimation. Second, using insights from the statistical properties of cascading blackouts, we propose a method for facilitating non-local message passing in our GNN models. We validate these two approaches on a large simulated dataset, and show the potential of both to increase blackout size estimation performance.
Ultrafast CMOS image sensors and data-enabled super-resolution for multimodal radiographic imaging and tomography
Jan 27, 2023



We summarize recent progress in ultrafast Complementary Metal Oxide Semiconductor (CMOS) image sensor development and the application of neural networks for post-processing of CMOS and charge-coupled device (CCD) image data to achieve sub-pixel resolution (thus $super$-$resolution$). The combination of novel CMOS pixel designs and data-enabled image post-processing provides a promising path towards ultrafast high-resolution multi-modal radiographic imaging and tomography applications.
Word-Graph2vec: An efficient word embedding approach on word co-occurrence graph using random walk sampling
Jan 17, 2023Word embedding has become ubiquitous and is widely used in various text mining and natural language processing (NLP) tasks, such as information retrieval, semantic analysis, and machine translation, among many others. Unfortunately, it is prohibitively expensive to train the word embedding in a relatively large corpus. We propose a graph-based word embedding algorithm, called Word-Graph2vec, which converts the large corpus into a word co-occurrence graph, then takes the word sequence samples from this graph by randomly traveling and trains the word embedding on this sampling corpus in the end. We posit that because of the stable vocabulary, relative idioms, and fixed expressions in English, the size and density of the word co-occurrence graph change slightly with the increase in the training corpus. So that Word-Graph2vec has stable runtime on the large scale data set, and its performance advantage becomes more and more obvious with the growth of the training corpus. Extensive experiments conducted on real-world datasets show that the proposed algorithm outperforms traditional Skip-Gram by four-five times in terms of efficiency, while the error generated by the random walk sampling is small.
A Monotonicity Constrained Attention Module for Emotion Classification with Limited EEG Data
Aug 17, 2022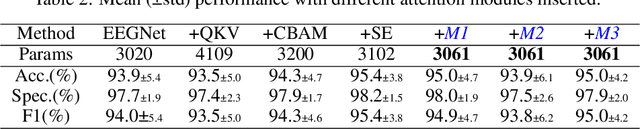
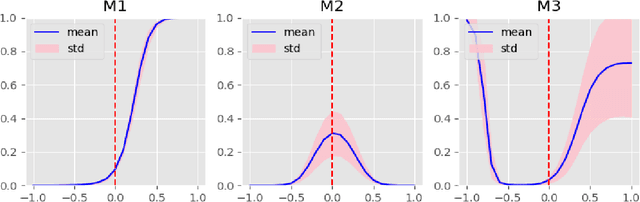
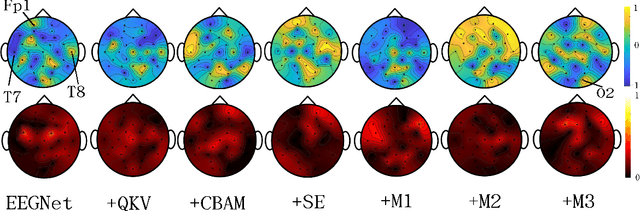
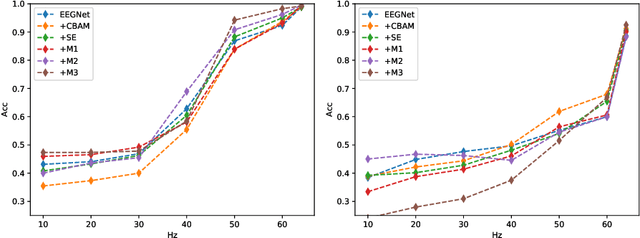
In this work, a parameter-efficient attention module is presented for emotion classification using a limited, or relatively small, number of electroencephalogram (EEG) signals. This module is called the Monotonicity Constrained Attention Module (MCAM) due to its capability of incorporating priors on the monotonicity when converting features' Gram matrices into attention matrices for better feature refinement. Our experiments have shown that MCAM's effectiveness is comparable to state-of-the-art attention modules in boosting the backbone network's performance in prediction while requiring less parameters. Several accompanying sensitivity analyses on trained models' prediction concerning different attacks are also performed. These attacks include various frequency domain filtering levels and gradually morphing between samples associated with multiple labels. Our results can help better understand different modules' behaviour in prediction and can provide guidance in applications where data is limited and are with noises.
High-resolution chirplet transform: from parameters analysis to parameters combination
Aug 02, 2021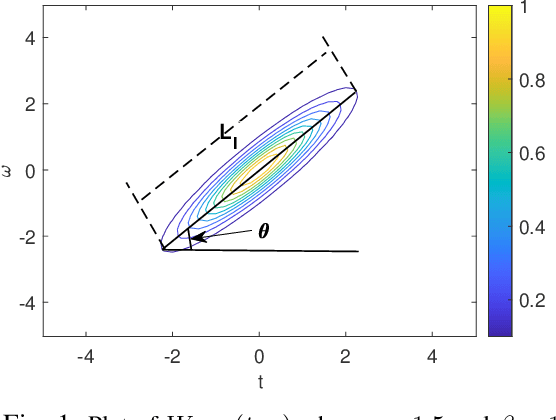
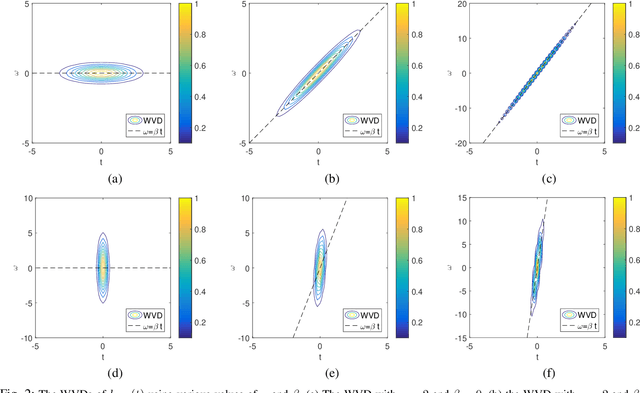
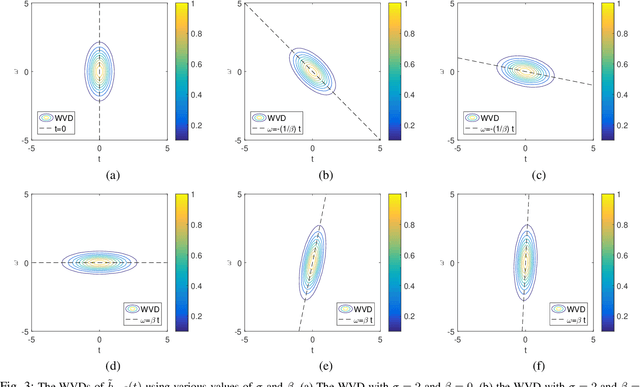
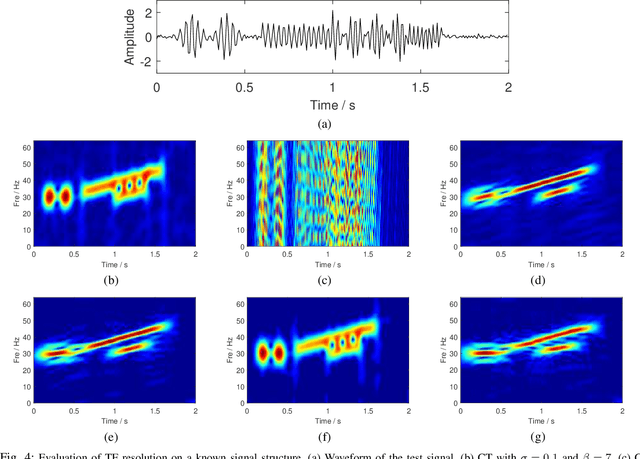
The standard chirplet transform (CT) with a chirp-modulated Gaussian window provides a valuable tool for analyzing linear chirp signals. The parameters present in the window determine the performance of CT and play a very important role in high-resolution time-frequency (TF) analysis. In this paper, we first give the window shape analysis of CT and compare it with the extension that employs a rotating Gaussian window by fractional Fourier transform. The given parameters analysis provides certain theoretical guidance for developing high-resolution CT. We then propose a multi-resolution chirplet transform (MrCT) by combining multiple CTs with different parameter combinations. These are combined geometrically to obtain an improved TF resolution by overcoming the limitations of any single representation of the CT. By deriving the combined instantaneous frequency equation, we further develop a high-concentration TF post-processing approach to improve the readability of the MrCT. Numerical experiments on simulated and real signals verify its effectiveness.